
pkb contents > databases | just under 4807 words | updated 12/29/2017
These notes are heavily influenced by Dr. Simon Wu-Ping Wang's slides as well as Connolly and Begg (2015).
A database is a either (1) collection of data that's structured according to a data model (usually relational, as discussed below; see notes on information structures for other major data models); or (2) this structured data plus a database management system (DBMS).
A DBMS is either a database engine for interacting with the database plus a database frontend for user interaction, per definition (1) above; or these two things plus a database, per definition (2) above. A DMBS may be desktop-based (Access, FileMaker Pro) or server-based (SQL Server, Oracle, DB2, MySQL, PostgreSQL). Typical DBMS offer:
Finally, a database system is a database/DBMS plus database applications (any applications that source from or feed data to the database). This term denotes only the technical environment of a database; the full database environment encompasses hardware, software, data, procedures, and people.
| Requirements Analysis | |
|---|---|
| Design | Conceptual |
| Logical | |
| Physical | |
| Development | Implementation |
| Testing | |
| Administration | Rollout |
| Support | |
The first computerized information systems (IBM, c. 1950) imitated hierarchical paper filing systems. The more semantically powerful graph AKA network data model followed shortly thereafter (1960s, also IBM). In early systems, file and data formats were specific to an application or language; applications were specific to a department. This arrangement led to
Hierarchies and graphs were superseded by Edgar Codd's relational data model, proven in the 1970s and implemented in the 1980s. A relational database addresses the aforementioned problems because it is centralized (reducing redundancy, improving consistency, enabling data integration) and abstracted (available as a black box to interface with many different applications; offering an accessible language for ad hoc queries). It also:
Object databases introduced features like encapsulation and polymorphism c. 1990, but never became popular or standardized. With the advent of Big Data, NoSQL databases (an umbrella term for non-relational database with SQL-like interface) have become popular because they beat relational DBs at quick search; however, relational databases are still better at maintaining data integrity (via transaction management with ACID properties).
This is one way of thinking about database abstraction/separation, which, in general, makes the database easier to change and maintain by providing data independence:
Then, the DBMS creates mappings (also called intensions; a realization of a schema is called the extension or state of the database) between schemas.
In a relational database, the data model is of tables AKA relations, which can be clustered tables or heaps depending on their indexing. Tables have rows (AKA tuples, records) and columns (AKA attributes, fields). The order of rows and columns is insignificant (unless an index is created).
Representing reality in terms of entities, attributes and relationships occurs during the conceptual design phase of database development. Per Ullman (2006), many different relational schemas could be used to model any given reality; the best designs will suit the underlying business processes and be in a normal form.
The relationship between two entites has several characteristics. The participation of a relationship is mandatory or optional; the cardinality AKA modality of a relationships may be one-to-one, one-to-many, or many-to-many; see ERDs for notation. A relationship is identifying if the PK of a parent entity appears in the PK of a child entity, denoted with a solid line; nonidentifying relationships are denoted with dashed lines.
Many-to-many relationships must be resolved with an associative entity (AKA junction table) that has a combined primary key (PK), both of which are foreign keys (FK)---though there are arguments for and against creating a synthetic key for an associative entity. For example, consider a taxi company that owns cars; employs drivers; randomly assigns each driver a car for their shift; and wants to maintain a record for liability purposes. Entities CAR and DRIVER have a many-to-many relationship, since a driver will be assigned to multiple cars over the course of their employment and a car will likewise be driven by many different drivers. To capture the necessary data, SHIFTS is created as an associative entity with attributes driver ID, car ID, and shift date.
Entities may be classified as superclasses and subclasses; this provides more semantic meaning to an ER model, makes the ER model more readable, and (depending on implementation) can reduce the number of NULLs in the database. There are several implementation options:
Per Sunderraman (2012) and the Database Management Wikia (n.d.), an attribute is:
Different sorts of relationships AKA dependencies exist between attributes; this is not a modeling decision, it is a feature of the real world. Dependencies are important for understanding normalization; normalization is a process of allocating attributes to entities to achieve a certain configuration of dependencies within each entity. Dependencies are also used (somehow?) in DB compression and query optimization.
A functional dependency
A → B
exists when the same A (for our purposes, an attribute value called the
determinant)
is linked to a single B (another attribute value, called the
dependent).
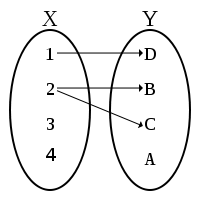
The reverse is not necessarily true. Note that this is like a mathematical function, where each x, a function input, must correspond to exactly one y, a function output, but a single value of y might correspond to multiple different values of x:
| This is a Function | This is Not a Function |
|---|---|
|
|
|
Written in predicate logic with tuples denoted t and u, attributes denoted A and B, a functional dependency exists if, for
∀ t,u ∈ R, t.A = u.A ⇒ t.B = u.B
; this generalizes to multiple attributes, such that a determinant is best (i.e., worst) defined as (an) attribute(s) whose value(s) determine(s) the value(s) of a second (set of) attribute(s). There are a few special cases:
A → B & B ⊆ A
A → B & B ⊈ A
A → B & A ∩ B = ∅
The set of attributes that are functionally dependent on a determinant is called the determinant's
closure,
{A}*.
A closure can obviously be as small as a single attribute. Per displayName (2015), a determinant whose closure is the
entire table
is a
candidate key
AKA identity value; one candidate key is chosen as the table's sole
primary key (PK).
This is an excellent demonstration of identifying (super) keys.
In general, keys may be natural, i.e. present in the data, or synthetic AKA surrogate, automatically generated by the database for internal use. Keys may also be composite AKA concatenated, meaning that several attributes taken together (a set) are a determinant whose closure is the entire table. For primary keys specifically, they are most often an integer (the narrowest suitable field); immutable; and mandatory.
If a functional dependency exists between X and Y, and a functional dependency exists between Y and Z, then a transitive dependency exists between X and Z:
A → B & B → C ⇒ A → C.
As an example, consider a table (perhaps in a bookstore database) with three attributes: ISBN, TITLE, AUTHOR, PHONE NUMBER. ISBN is the primary key; TITLE and AUTHOR are functionally dependent on it; but PHONE NUMBER is functionally dependent on AUTHOR, not on ISBN. Therefore a transitive dependency exists between PHONE NUMBER and ISBN.
A multivalued dependency
A ↠ B
exists if all tuples share their A attributes; tuple v shares B attributes with t, and its remaining attributes with u; tuple w shares A attributes with u, and its remaining attributes with t. In predicate logic:
if ∀ t,u∈R | t.A = u.A then ∃ v∈R | v.A=t.A and v.B=t.B and v.rest=u.rest.
Furthermore,
∃ w∈R | w.A=t.A and w.B=u.B and w.rest=t.rest
. MVDs matter for 4NF;
examples and details here.
Data must have integrity to be useful and trustworthy. Data integrity tends to erode, and a database has mechanisms for maintaining it in its various forms:
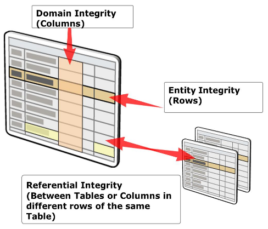
Additionally, database designs are normalized to preserve integrity and minimize redundancy (by limiting storage costs).
Normalization is a process of allocating attributes to entities to achieve a certain configuration of dependencies within each entity; Bill Kent does a good job talking about this in terms of which attributes provide "facts" about other attributes. There are five but actually maybe six levels of normalization, with third normal form the commonly accepted target. The first normal form is how Codd articulated his relational data model in the 1970s, with the other forms progressive refinements of the basic relational model:
A → B,
A is the PK.
This
example from ThoughtCo
shows how normal forms prevent anomalies. In this case there are two FDs
(Book → Author, Author → Author_Nationality)
and one TD
(Book → Author_Nationality),
plus a violation of 1NF's atomic field requirement:
| Author | Book | Author_Nationality |
|---|---|---|
| Orson Scott Card | Ender's Game | United States |
| Orson Scott Card | Children of the Mind | United States |
| Margaret Atwood | The Handmaid's Tale | Canada |
Note the redundancy---repeating pairs of (Orson Scott Card, United States), caused by the transitive dependency---and the liabilities it creates in the form of potential data loss and data corruption:
3NF creates several tables instead:
| AuthorID | Author_Firstname | Author_Lastname | Author_Nationality |
|---|---|---|---|
| 01 | Orson Scott | Card | United States |
| 02 | Margaret | Atwood | Canada |
| AuthorID | BookID |
|---|---|
| 01 | 001 |
| 01 | 002 |
| 02 | 003 |
| BookID | Book_Name |
|---|---|
| 001 | Ender's Game |
| 002 | Children of the Mind |
| 003 | The Handmaid's Tale |
Per Chapple (2016):
See notes on Big Data, an area in which NoSQL databases are commonly used.
A good design process minimizes redundancy; reduces errors by automating or imposing constraints on data entry; permits multiple analyses by replacing multipart fields with atomic ones; avoids data conflicts by reserving calculation to the analysis phase, rather than storing results; and ensures complete information by requiring it during input. Best practices for DB design:
Note that databases are often developed in parallel with the applications that will use them. Also, DB development may use CASE (computer-aided software engineering) tools that help with standardization, integration, consistency, and automation. For databases, CASE tools may provide forward engineering (generating database-creating code based on ERD) and reverse engineering (generating ERD from existing database; an efficient way of producing documentation).
All stages of design are beholden to the underlying data model. Conceptual design is broader, mostly focused on grouping attributes into tables; logical design is more granular, mostly focused on properties and constraints of each attribute. Lastly, physical design is focused on specifying the database and its interfaces, etc. according to a particular DBMS.
In the conceptual design stage of database development, there are two competing approaches:
Regardless, the end goal is a schema that is normalized to avoid anomalies.
In addition to constructing tables via a top-down or bottom-up approach, a conceptual design should:
Proceed table by table, field by field:
The goal of the physical design stage is to provide all the information necessary to build a database that takes advantage of features from the chosen platform. Physical design depends on DBMS-specific features, so consult notes on specific DBMS software; this discussion is based on MS SQL Server.
Source: Simon Wang
Source: Simon Wang
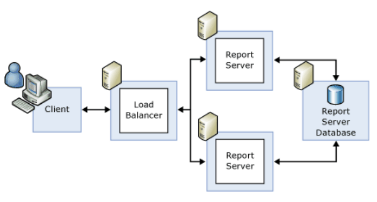
Source: Simon Wang
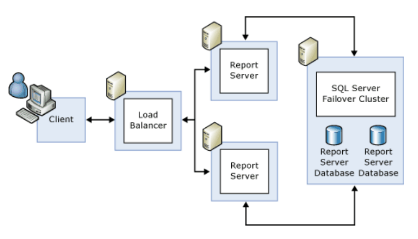
Source: Simon Wang
A DBMS records actions in its log file (.LDF) and data (as pages; see discussion on indexing and SQL Server files) in its data file. During backup, the local log file is wiped but the data files are unchanged.
MS SQL Server stores table data (rows) in uniformly-sized pages AKA blocks:

If the main data file (.MDF) exceeds its initially allocated space, there are several options:
Various kinds of indexes are created to accelerate queries (SELECT rows from pages) at the expense of write speed (INSERT, UPDATE, and DELETE operations). Per Sheldon (2014), not all indexes improve performance for all queries; more complex queries that involve grouping and sorting can suffer from a clustered index.
Because of this read/write tradeoff, indexes are most useful in reporting databases versus transactional databases. Alternatively, an index may be erased when loading a very large dataset into the database, then subsequently restored.
The PK is indexed by default, and commonly searched fields may be indexed as well. Many DBMS offer a query optimizer that identifies statistically when indexing would be beneficial. Often indexing a PK/FK pair will improve JOIN performance (and JOINs are very costly).
A table is either a heap or, if it has a clustered index, a clustered table. A heap is simply unsorted data pages; the order of its contents (i.e., how its rows are allocated across data pages) will be determined initially by data entry and then by DBMS-initiated changes (for efficiency's sake). A clustered index, on the other hand, introduces sorting that is implemented at the level of pages through row offset arrays AKA slot arrays; see Sheffield (2012). For this reason, there can be only one clustered index per table (PK by default).
To facilitate specific queries, both heaps and clustered tables may have multiple non-clustered indexes that provide alternate sort orders "very much like the index at the end of a book: it occupies its own space, it is highly redundant, and it refers to the actual information stored in a different place" (Winand, n.d.).
Just as heaps and clustered tables store their rows in data pages, non-clustered indexes store their leaf nodes in data pages. Via pointers, leaves are doubly connected to each other (to maintain sort order as rows are added and deleted) and also point to rows in the heap/clustered table (thereby making the index useful):
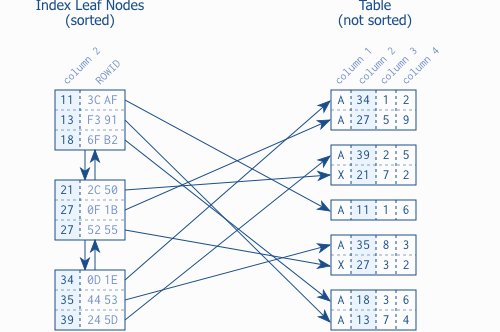
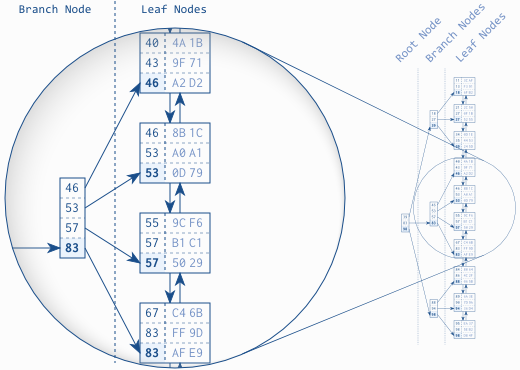
For heap pages, clustered indexes, and non-clustered indexes alike, a B-tree AKA balanced tree structure with root and intermediary nodes is used to make page search more efficient:
Finally, while heaps, clustered indexes, and non-clustered indexes use a rowstore structure (Sheldon, 2013), a columnstore index (useful for read-heavy databases with star or snowflake schemas, i.e. BI warehouses) searches only relevant columns:

Index fragmentation is inevitable, especially in OLTP environments:
Fragmentation can be detected with a DBMS tool, then repaired:
| Characteristic | Reorganize | Rebuild |
|---|---|---|
| Online or offline | Online | Offline as default; online as option |
| Internal fragmentation | Yes | Yes |
| Logical fragmentation | Yes | Yes |
| Transaction atomicity | Small discrete transactions | Single atomic transaction |
| Rebuild statistics automatically | No | Yes |
| Parallel execution | No | Yes |
| Untangle indexes that are interleaved with the data file | No | Yes |
| Transaction log space used | Less | More |
| Additional free space required in the data file | No | Yes |
Common security threats may be categorized by human vectors or by system targets:
| Users | Developers | Administrators |
|---|---|---|
|