
pkb contents > information architecture | just under 4887 words | updated 12/28/2017
IR occurs when a user retrieves information objects AKA content objects (documents and metadata) from an information retrieval system (e.g. libraries, archives, repositories/portals, websites, databases). IR requires IA.
Information professionals work to ensure that IR (1) has good precision, AKA 'satisfies the requirement for general survey' or 'satisfies the collocating requirement' or attains 'representational predictability'; (2) has good recall; and (3) is possible across multiple IR systems. They do this by (1) creating search algorithms or by (2) ingesting information objects into a catalog, which includes:
CATALOGING the object, i.e. describing/representing an information object with metadata, including subject headings and subheadings. Subject headings and subheadings can be combined from the beginning (precoordination) or combined by users while searching (postcoordination)
INDEXING the object, i.e. mapping out the contents of an information object, perhaps using terms from a CV (at minimum, for named entities, an authority file should be consulted).
Although TAGGING or keywording is occasionally used as a synonym for indexing, it is more often used to denote the opposite of indexing, in which keywords emerge from an information itself rather than from an indexing language. This allows for a grassroots view of what something is about.
| INDEXING AGENT | ||||
|---|---|---|---|---|
| Taxonomist | Users | Machine | ||
| TAXONOMY | Yes | Closed | n/a | Auto-Tagging, Auto-Classification, Auto-Categorization |
| No | Open | Tagging | Information Extraction | |
To retrieve information, users engage with information systems by:
SEARCHING for a specific piece of information; this is the concern of back-end IA. Simultaneous search of multiple information systems is called metasearching, broadcast searching, cross-database searching, federated searching, and parallel searching.
BROWSING a collection of information; this is the concern of front-end IA, with the goal of intuitive user interfaces and navigational structures. Browsing is "quick examination of the relevance of a number of objects which may or may not lead to a closer examination or acquisition/selection of (some of) these objects" Hjørland (2011); "visually scanning through organized collections of representations of content objects" (ANSI/NISO Z39.19-2005, p. 157).
Rosenfeld, Morville, and Arango (2015) say that IA aims to facilitate both the finding and understanding of information. The "finding" dimension of IA is information retrieval, the legacy of library science; the "understanding" dimension comes via Richard Saul Wurman, who focused on making complex systems intelligible through structured presentation, visualization, etc.
Per Abrahamson and Freedman (2008), order (like all things) has both benefit and cost. Even setting feasibility aside, it's probably never the case that 100% order is optimal. At the same time, because individuals' organization strategies and preferences vary so much, shared information spaces must (?) be organized according to intelligible principles that prospective users of the space can access and learn.
Per Abrahamson and Freedman (2008):
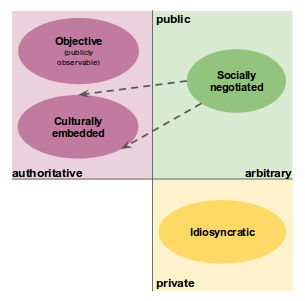
Hedden (2016) offers a typology in which taxonomies (i.e., knowledge organization structures) have different bases/origins. KOSs may be (1) objective, with obvious empirical basis; (2) socially-negotiated, perhaps eventually becoming (3) culturally embedded; or (4) idiosyncratic:
Schemas and structures work together. For example, my Zotero library is a hierarchy (structure) of topical categories (schema), automatically sorted by alphabet (schema). The distinction I draw is that "schemas" are for the conceptual (abstract, disembodied) organization of information into groups, whereas "structures" describe group configuration.
Wurman (1990) claims there are only five ways to organize items. Similarly, Wyllys (2000) states that information can be organized according to different schemas that encompass Wurman's five ways (italicized):
But, Wyllys adds, there are also three fundamental information structures, AKA data models: hierarchic, graph, and relational. In their review of database history, Connolly and Begg (2015) classify Wyllys' three structures as "record-based" and add "object-based" as another top-level category:
Can’t express constraints on the data, but express structure well.
Per Zeng (n.d.),
AKA networks, triples, ontologies. Enables explicit modeling of different kinds of relationships (Has, IsCreatedBy, etc.) as well as more relationships (not restricted to one parent). Records are also called nodes and segments; relationships are also called edges.
Tables with columns, implicitly related via attributes; see notes on relational databases.
Allow specification of constraints, but not overall structure. Objects are instances of classes; classes and objects have attributes (properties, characteristics, adjectives/nouns) and methods (actions, functions, behaviors, verbs).
Per Hedden, taxonomy --- the law or science (nomos) of order (taxis) --- has both general and specific meanings.
In general, taxonomy is the discipline of creating and managing taxonomies, a term synonymous with knowledge organization structures/systems (KOS) and very nearly synonymous with controlled vocabularies (CVs). As a field, taxonomy has roots in biological taxonomies and library catalogs (which existed even in antiquity as scrolls). Companies began to use taxonomies for corporate knowledge asset management very marginally in the 1980s, then increasingly in the 1990s as web technologies spread.
Beyond this general sense, taxonomies are also specific kinds of KOSs.
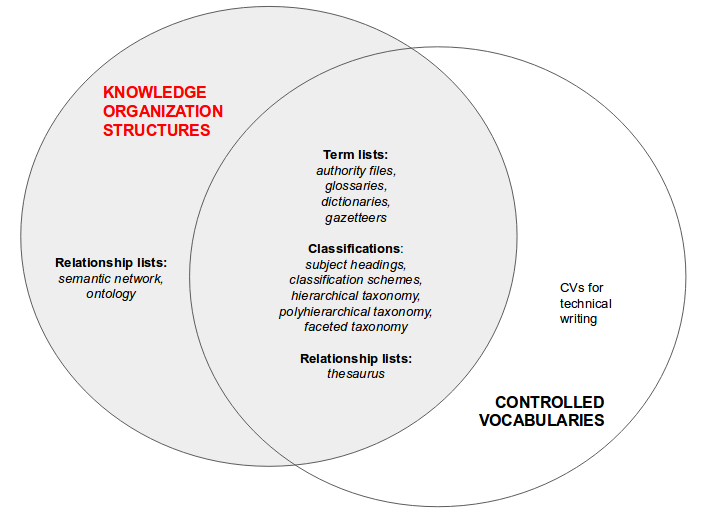
In order of increasing complexity (number, kind, and configuration of relationships):
| KOS | Ambiguity control | Synonym control | Hierarchical relationship | Associative relationship |
|---|---|---|---|---|
| Term list | X | |||
| Syn ring | X | X | ||
| Taxonomy | X | X | X | |
| Thesaurus | X | X | X | X |
Terms are meant to be atomic units of meaning---single or multi-word phrases.
Concepts are combinations of terms.
Term lists are essentially flat list, though they may include "See"/"Use" to steer people towards preferred language, or use a synonym ring approach (no preferred term among multiple).
Synonym rings AKA synsets associate synonyms without indicating preference for one over the others (equivalence relationship). Synsets are usually invisible to users, e.g. underpinning a search engine.
Taxonomies AKA hierarchies AKA hierarchical taxonomies AKA tree structures arrange terms into parent/child relationships beneath a single top term (TT). A strict hierarchy requires that each term have a single parent AKA broader term (BT), though they may have multiple siblings and children AKA narrower terms (NT).
Microcontrolled vocabularies are subsets of a controlled vocabulary, creating a specialist CV.
Faceted taxonomies are a bottom-up approach to providing multiple views of the same content objects, based on shared attributes like topic, location, format, author, etc. They are often presented as navigation aids or search refinments; they may also be used to organize very large controlled vocabulary.
Polyhierarchies are hierarchies in which children may have multiple parents.
Thesauri capture associative relationships AKA related terms (RT) in addition to equivalence (U/UF) and hierarchical (BT/NT) relationships. Relationships are also called cross-references; they should be reciprocal (explicit entry at term Y linking to term X, explicit entry at term X linking to term Y) and may or may not be symmetric. Thesauri are useful for representing a very large controlled vocabulary.
Semantic networks fall short, in some way, of full ontologies, which are defined by their:
Relevant technologies include RDF, OWL, and topic maps.
As part of ingesting a content object into an information system, KOSs can be applied to the content object at several levels, creating more or less granular pictures of what the object is about:
Information consumers depend on KOSs to browse and search content objects:
See also uses of CVs.
Reference works are information-dense resources meant to be consulted for specific information, not read comprehensively. Terminology for reference works is reviewed here because it often overlaps with KOS terminology. Definitions are quoted/paraphrased from Wikipedia:
CVs (AKA authority lists) consist of terms, syntax (how terms may be combined), and term records containing each term's semantic relationships, scope notes, and history notes.
Controlled vocabularies stand in contrast with natural languages, which undermine information retrieval because they are fraught with polysemes* (ambiguous words --- both homographs and synonyms/near-synonyms/quasi-synonyms). At minimum, to avoid the IR pitfalls of natural languages CVs must:
* Why so many polysemes in natural language?
Svenonius (2005), also see KOSs by role in IR: "In the form of terminological databanks, CVs are used to assist in both manual and automatic translation. In the form of glossaries, they standardize and explicate the meaning or usage of terms in specialized fields of activity. In the form of literary thesauri they assist in composition by facilitating the expression of ideas. In the form of conceptual structures they give backbone to knowledge representation systems."
Per ANSI/NISO Z39.19 (p. 19),
Terms are chosen from a specific domain/information space if their inclusion is warranted:
Since warrants shift over time, there should be a 'parking lot' for candidate terms AKA provisional terms. Terms can be generated by a committee (top-down, bottom-up); by empirical methods (deductive, inductive); by a machine; or from an existing CV (don't duplicate effort!).
The basic rule per ANSI/NISO Z39.19 is that a term should denote a single concept or unit of thought; this is challenged by Svenonius (2005), who argues that concepts are inherently fuzzy and that quantitative linguistics provides a more objective foundation for extracting terms from natural language. At any rate, there are different kinds of concepts:
The simplest term form is a single-word term; there are several kinds of multiword AKA compound terms, the construction of which is governed by the CV's syntax:
A (1) bound term uses multiple words or a phrase to denote a single concept, e.g. oral surgery. The inverted form of bound terms may be included as an entry term, e.g. surgery, oral: see oral surgery. These (a) naturally occurring compound terms are generally preferable to (b) qualified homographs --- for example, religious tolerance is generally better than tolerance (religious). If no bound compound term exists, ambiguous terms (AKA head or focus nouns) should receive a modifier (AKA difference). Additionally, the scope of any term, not just homographs, may be clarified with a scope note (SN). If a SN mentions another term in the vocabulary, it should receive a reciprocal SN or cross-reference: term2: X SN term1.
While compound terms denote a single concept, (2) coordinated terms AKA synthesized terms associate several concepts with a single information object and generally fall in the domain of indexing languages. Coordinated terms can be (a) embedded in the object (precoordination), as with Library of Congress subject headings in books: English Language--Rhetoric, Persuasion (Rhetoric), Report Writing. Precoordinated terms enable browsing with great specificity, describe complex concepts, and impose alphabetic proximity on related terms that would otherwise be far apart. Given the high cost of taxonomist labor, though, it's often better to let users (b) combine terms interactively during search (postcoordination), e.g. English Language AND Rhetoric AND Persuasion AND Report Writing.
Use of a compound term should be determined by warrant, total #terms in the CV (more compound terms means more overall terms), and intended format (print sometimes benefits from precoordinated terms); see ANSI/NISO Z9.19 pp. 39-40 for more guidance and examples.
*Svenonius (2005) explains the intended effect of this standard: CVs where every term is "context independent", i.e. self-contained and thus reusable. However, context independence is "not normally operative in classification schemes where the verbal headings are governed by the principle of hierarchical force."
All relationships are reciprocal, which should be captured by the taxonomy software. Most relationships (except RT) are asymmetric. Orphan terms lack any relationship.
Synonyms, near-synonyms, lexical variants, and (when generic posting is practiced) child terms are subsumed into a single preferred term with USE/USED FOR or U/UF. Preferred terms are also called descriptors and headings; non-preferred terms are also called entry or lead-in terms.
See discussion of hierarchy, above.
Associative relationships should be recorded between terms that are needed to explain each other, or readily evoke each other, or are etymologically related, or are derived one from the other. Although they may be disambiguated in a graph database, in a thesaurus the following relationships (and more) are collapsed under RELATED TERM/RT:
Per ANSI/NISO Z39.19 (p. 16),
The usability and IR performance of CVs should be tested:
Documentation should cover:
CVs must be updated to stay valid, so there should be plan for reviews at defined intervals.
Updates may include:
ANSI/NISO Z39.19 (pp. 99-102) lists desirable features of CV management software:
Per ANSI/NISO Z39.19, the need for interoperability arises from different sources:
Interoperability may be approached in different ways:
Interoperability data may be stored in:
Abrahamson, E. & Freedman, D. H. (2008). A perfect mess: The hidden benefits of disorder --- How crammed closets, cluttered offices, and on-the-fly planning make the world a better place. New York City, NY: Back Bay Books.
AfterHoursProgramming.com. (n.d.) IA tutorial. Retrieved from http://www.afterhoursprogramming.com/tutorial/Information-Architecture/Overview/
ANSI/NISO. (2005). Z39.19-2005: Guidelines for the construction, management, and format of monolingual controlled vocabularies. Retrieved from http://www.niso.org/apps/group_public/download.php/12591/z39-19-2005r2010.pdf
Connolly, T. & Begg, C. (2015). Database systems: A practical approach to design, implementation, and management (6th ed.). New York City, NY: Pearson Education.
Hedden, H. (2016). The accidental taxonomist (2e). Medford, NJ: Information Today, Inc.
Hjørland, B. (2011). Theoretical clarity is not "Manicheanism": A reply to Marcia Bates. Journal of Information Science, 37(5), 546-552. Retrieved from http://pure.iva.dk/files/31053333/JIS_1568_v3.pdf
Jacob, E. K. (2004). Classification and categorization: a difference that makes a difference. Library Trends, 52(3), 515. Retrieved from https://pdfs.semanticscholar.org/774e/ab27b22aa92dfaa9aeeeafbe845058e85f58.pdf
NISO. (1997). TR02-1997: Guidelines for indexes and related information retrieval devices. Retrieved from http://www.niso.org/publications/tr/tr02.pdf
Pomerantz, J. (2015). Metadata. The MIT Press Essential Knowledge Series. Boston, MA: MIT Press.
Rosenfeld, L., Morville, P., & Arango, J. (2015). Information architecture for the web and beyond (4e). Sebastopol, California: O'Reilly Media.
Svenonius, E. (2005). Design of controlled vocabularies. Encyclopedia of Library and Information Science, 45 (10), 82–109. Retrieved from http://polaris.gseis.ucla.edu/gleazer/260_readings/Svenonius.pdf
UX Booth. (2015). A complete beginner's guide to information architecture. Retrieved from http://www.uxbooth.com/articles/complete-beginners-guide-to-information-architecture/
Wurman, R. S. (2014). Give yourself permission to follow your nose [video]. Retrieved from https://www.youtube.com/watch?v=SDm1zXxpkr8
Wurman, R. S. (1990). Information anxiety. New York City, NY: Bantam Books.
Wurman, R. S. (1997). Information architects. New York City, NY: Graphis Inc.
Wyllys, R. E. (2000). Information architecture. Retrieved from https://www.ischool.utexas.edu/~l38613dw/readings/InfoArchitecture.html
Zeng, M. (n.d.). 4.3 Hierarchical relationships. In Construction of controlled vocabularies: A primer. Retrieved from http://marciazeng.slis.kent.edu/Z3919/43hierarchy.htm