pkb contents
> search engines | just under 2262 words | updated 12/29/2017
"Technically, 'search engine' is the popular term for information retrieval systems. Although Web search engines are the most popular, search engines are often used in other than the Web, such as desktop search engines and document search engines ... perhaps a more appropriate name for them would have been
finding engines"
(Sharda et al., 2014, p. 243).
Per Sharda et al. (2014, pp. 246-248), SEO is the "intentional activity of affecting the visibility of an e-commerce site or a Web site in a search engine's natural (unpaid or organic) search results ... As an Internet marketing strategy, SEO considers how search engines work, what people search for, the actual search terms or keywords typed into search engines, and which search engines are preferred by their targeted audience. Optimizing a Web site may involve editing its content, HTML, and associated coding to both increase its relevance to specific keywords and to remove barriers to the indexing activities of search engines. Promoting a site to increase the number of backlinks, or inbound links, is another SEO tactic."
-
"Cross-linking between pages of the same Web site to provide more links to the most important pages"
-
"URL normalization of Web pages so that they are accessible via multiple URLs and using canonical link elements and redirects"
-
"Writing content that inclues frequently searched keyword phrases"
-
"Updating content so as to keep search engines crawling back"
-
"Adding relevant keywords to a Web page's metadata"
From VanFossen (2006), some more SEO tactics:
-
Website/blog optimization:
-
Optimize your code → “HTML/XHMTL errors, lack of connecting and navigational links, lack of text, a table-based design, 404 page not found errors or other dead or moved links, and bad Apache .htaccess or robots.txt files.”
-
Develop strong intrasite links
-
Write with strong keyword usage: “Make sure that all links and images have TITLE and ALT attributes, and again put some of your keywords in their titles and descriptions.”
-
Use categories and tags
-
Use ping services → already built in to Wordpress
-
Blog promotion:
-
Submit via pings
-
Submit to search engines and directories
-
Become active and visible → e.g., comment on others’ posts
-
Build incoming links and reputation
-
Track SEO efforts & results:
-
Understand visitor and traffic statistics
-
Analyze visitor length of stay
-
Analyze referers
-
Analyze search keywords
-
Analyze most popular posts
-
Check your PageRank
-
Research competitors:
-
Study your competitors
-
Check who is linking to your competitors → Google search: link:http://site.address
-
Learn from their techniques and content
-
Maintain your site:
-
Develop strong annual site maintenance plans
-
Check code, dead end links, and other site maintenance on a regular schedule
Per Sharda et al., (2014), 'black-hat SEO' tactics include cloaking (crawler and human see different versions of a page) and using HTML, JavaScript, etc. to create content that a crawler sees but a human doesn't (e.g., through text color).
Per VanRossen, in 2005(b) Google used the following factors to rank websites, implying some SEO practices:
-
Number and quality of incoming links, where quality determinations are based on the page rank & age of the linking page
-
Link anchor text, which should echo keywords (but a variety of them)
-
If you have a blogroll set it so that it randomizes a partial selection from your whole blogroll
-
Keep your domain name for as long as possible
-
Click through rate to your site (especially your fresh content) from other sites, and from your site to ads
-
Consistent and moderately frequent content addition matters more than volume
-
How long users linger
-
Avoid tables in favor of CSS
Per VanRossen (2005a):
-
“Words inside of HTML heading tags get extra points when they match the keywords within your post, post title, post links, and image tags.”
-
Repetition of keywords is really important
-
“Putting keywords in titles, links, headings, tags, and throughout the page is still critical to the success of your site’s page ranking and keyword ranking results”
VanRossen (2005c):
-
"According to experts, your keyword density for a single word should be less than 12%, though many recommend 3-10% to be safe."
-
Ask: what keywords do people use to get to your site already?
-
Ask: what keywords do your competitors use? (comparison tool)
-
(Who are your competitors? Check
DMOZ
and
All The Web
to find other sites by category)
Tools:
Re: long-tail (uncommon) keywords,
-
http://www.wordtracker.com/academy/keyword-research/technical-guides/three-good-reasons-to-target-long-tail-keywords
-
http://blog.hubspot.com/blog/tabid/6307/bid/28912/The-Ultimate-Guide-for-Mastering-Long-Tail-Search.aspx
-
http://okdork.com/2014/04/21/why-content-goes-viral-what-analyzing-100-millions-articles-taught-us/
-
http://buzzsumo.com/
-
https://blog.bufferapp.com/social-media-stats-studies
-
http://time.com/12933/what-you-think-you-know-about-the-web-is-wrong/
-
https://blog.bufferapp.com/perfect-blog-post-research-data
-
https://moz.com/blog/the-generational-content-gap-three-ways-to-reach-multiple-generations
-
https://moz.com/blog/how-to-conduct-creative-content-research
-
http://www.svmsolutions.com/blog/content-marketing-what-should-you-write-about
-
http://www.komarketingassociates.com/blog/5-content-marketing-hacks-cheat-sheet-content-brainstorming/
-
http://visual.ly/portrait-content-marketer-more-marketer
-
http://blogs.timesofindia.indiatimes.com/Citycitybangbang/in-praise-of-un-marketing/
-
https://www.scoop.it/
-
https://paper.li/
Good (2014), a content
curator
is distinguished from a content marketer in the following ways; he [sic]:
-
"Is not after quantity. Quality is his key measure.
-
Does not ever curate something without having thoroughly looked at it, multiple times.
-
Always provides insight as to why something is relevant and where the item fits in its larger collection (stream, catalog, list, etc.)
-
Adds personal evaluation, judgment, critique or praise.
-
Integrates a personal touch, in the way it presents the curated object.
-
Provides useful information about other related, connected or similar objects of interest.
-
Credits and thanks anyone who has helped in the discovery, identification and analysis of any curated item and links relevant names of people present in the content.
-
Does not ever republish content “as is” without adding extra value to it.
-
Does not curate, select, personalize or republish his own content in an automated way.
-
Discloses bias, affiliation and other otherwise non self-evident contextual clues."
Or, the short version: “[never] forget what these people are looking for and what they really expect from anyone providing them with an answer”;“[take] seriously the information needs of your niche”.
Kanter (2013) provides an excellent summary (as she must) of how curation adds value to information:
-
From Ross Dawson:
-
Filtering:
Identifying groups of good sources or key words – so you can laser in on the topic
-
Validation:
Knowing your sources and their level of expertise
-
Synthesis:
Combining ideas and themes or boiling down a lot of information into a summary
-
Presentation:
Putting resources together – the ordering, sub-categories, and aesthetics
-
Customization:
Changing the title, context, or revising some of the ideas to match your audience’s needs
-
From James Mangan:
-
Practice and experiment:
Read the article and try the technique and describe how it worked or didn’t for you
-
Answer the question yourself:
Answer the question raised in the article from your own experience
-
Change your perspective:
Describe the article or resource from a different perspective
-
From Robin Good:
-
Comparing:
Compare the strengths and weaknesses of different sources
-
Finding related items:
Search and find other sources or articles that are talking about the same idea, putting the resource into a different context
-
Illustrating / Visualizing:
Add an illustration to the resource or collection
-
Evaluating:
Rate and rank items in your collection
-
Crediting & Attributing:
Giving credit to the original source
-
From R. W. Paul, re: critical thinking:
-
Clarification:
How can the information be explained in another way? Is it accurate? It is well organized? Is it missing something?
-
Assumptions:
What are the writer’s assumptions? Can we verify or disapprove the assumption?
-
Reasons and Evidence:
What are some other examples of this idea? Is the same as something else?
-
Viewpoints and Perspectives:
What is another way to look at this idea? Is it the best? Why or why not? What are the strengths and weaknesses? What would be an alternative? What is the counter argument?
-
Implications and Consequences:
What generalization can or can’t be made? How does this tie into what I already know about the topic?
-
Questions about Questions:
Why is x important? What does this mean?
Per Daly (2015):
-
Identify and automate the collection of good content
-
Get inspired by top-notch curators
-
NextDraft
-
Digg
-
Longreads
-
Drudge Report
-
The Verge
-
Nieman Journalism Lab
-
Digiday
-
Establishing a well-trafficked blog takes 6-12 months; be patient, consistent, and promote the blog through links and complementary media channels
AKA SEM; paid search
Per EBizMBA,
based on 2017 traffic data from Alexa, Compete, and Quantcast, ordered most to least popular:
-
Google
-
Bing
-
Yahoo
-
Baidu
-
Ask
-
AOL Search
-
DuckDuckGo
-
WolframAlpha
-
Yandex
-
WebCrawler
-
Search
-
dogpile
-
ixquick
-
excite
-
Info
-
Information overload
-
Privacy vs. personalization
-
Political & cultural influences on search
-
Effect on traditional media
-
Social networks as IR tools
-
Adversarial IR (spam)
In general, search engines work by crawling and
automatically indexing
content, thus creating metadata. This index may be fairly shallow, e.g. based on contents of the
tag or headers; it may also be quite deep, using natural language process (NLP) techniques like grammatical stemming. User search terms are then matched to the index.
In the early days, there was a strong distinction in techniques used between search engines and library catalogs. Increasingly, though,
KOSs from IA
--- which take advantage of human knowledge by formalizing it for use by an information system --- play a role in improving search engine performance.
Per Sharda et al. (2014, pp. 243-246), a search engine involves two simultaneous cycles: "[w]hile one is interfacing with the World Wide Web, the other is interfacing with the user."
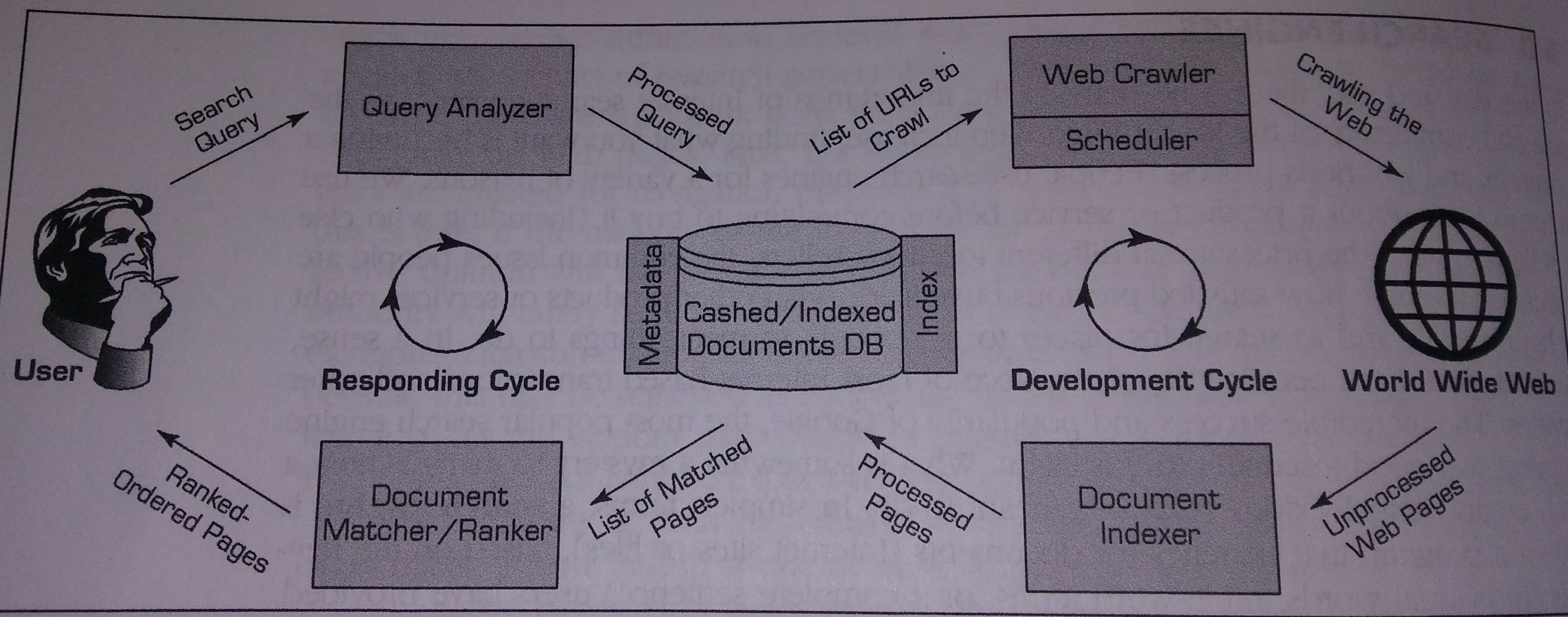
(AKA Web spider, spider)
"A Web crawler starts with a list of URLs to visit, which are listed in the schedule and are often called the
seeds.
These URLs may come from submissions made by Webmasters, or, more often, they come from the internal hyperlinks of previously crawled documents/pages. As the crawler visits these URLs, it identifies all the hyperlinks in the page and adds them to the list of URLs to visit. As the documents are found and fetched by the crawler, they are stored in a temporary staging area for the document indexer to grab and process."
-
Pre-processing
-
format conversions
-
separation of different content types
-
Parsing the documents
"[R]esponsible for receiving a search request from the user (via the search engine's Web server interface) and converting it into a standardized data structure, so that it can be easily queried/matched against the entries in the document database ... quite similar to what the document indexer does ..."
Per some
search algorithm,
-
Identify eligible results
-
Return results,
ranked by relevance
"Leading search engines like Google monitor the performance of their search results by capturing, recording, and analyzing postdelivery user actions amd experiences. These analyses often lead to more and more rules to further refine the ranking of the documents/pages so that the links at the top are more preferable to the end users" (Sharda et al., 2014, p. 246).
Per Sharda et al. (2014):
-
Effectiveness AKA quality of results
-
Efficiency AKA speed
"[E]arly search engines used a simple keyword match against the document database and returned a list of ordered documents/pages, where the determinant of the order was a function that used the number of words/terms matched between the query and the document along with the weights of those words/terms" (Sharda et al., 2014, p. 246)
-
Developed by Google in 1997
(or Hypertext Induced Topic Selection??)
(semantic reasoning and query rewriting)
(machine learning)
Daly, J. (2015, May 5). How to write a great roundup post. Retrieved from
http://www.cornerstonecontent.com/how-to-write-a-great-roundup-post/
Good, R. (2014, March 18). Content curation is not content marketing. MasterNewMedia. Retrieved from
http://www.masternewmedia.org/content-curation-is-not-content-marketing/
Kanter, B. (2013, December 13). How nonprofits get significant value from content curation. Beth's Blog. Retrieved from
http://www.bethkanter.org/content-curation-2/
Sharda, R., Delen, D., & Turban, E. (2014).
Business intelligence: A managerial perspective on analytics
(3rd ed.). New York City, NY: Pearson.
VanFossen, L. (2005a, October 16). How people search the web, and how they can find your blog. Retrieved from
https://lorelle.wordpress.com/2005/10/16/how-people-search-the-web-and-how-they-can-find-your-blog/
VanFossen, L. (2005b, September 19). Secret out -- How Google ranks websites. Retrieved from
https://lorelle.wordpress.com/2005/09/19/secret-out-how-google-ranks-websites/
VanFossen, L. (2005c, November 26). What are keywords? Retrieved from
https://lorelle.wordpress.com/2005/11/26/what-are-keywords/
VanFossen, L. (2006, January 15) Do-It-Yourself Search Engine Optimization. Retrieved from
https://lorelle.wordpress.com/2006/01/15/dyi-search-engine-optimization/
Hedden, H. (2016).
The accidental taxonomist
(2e). Medford, NJ: Information Today, Inc.